Tag: calibre
Platypus?
Calibre webscraping app
My python script to run my web update can be made into an app using platypus.
Settings: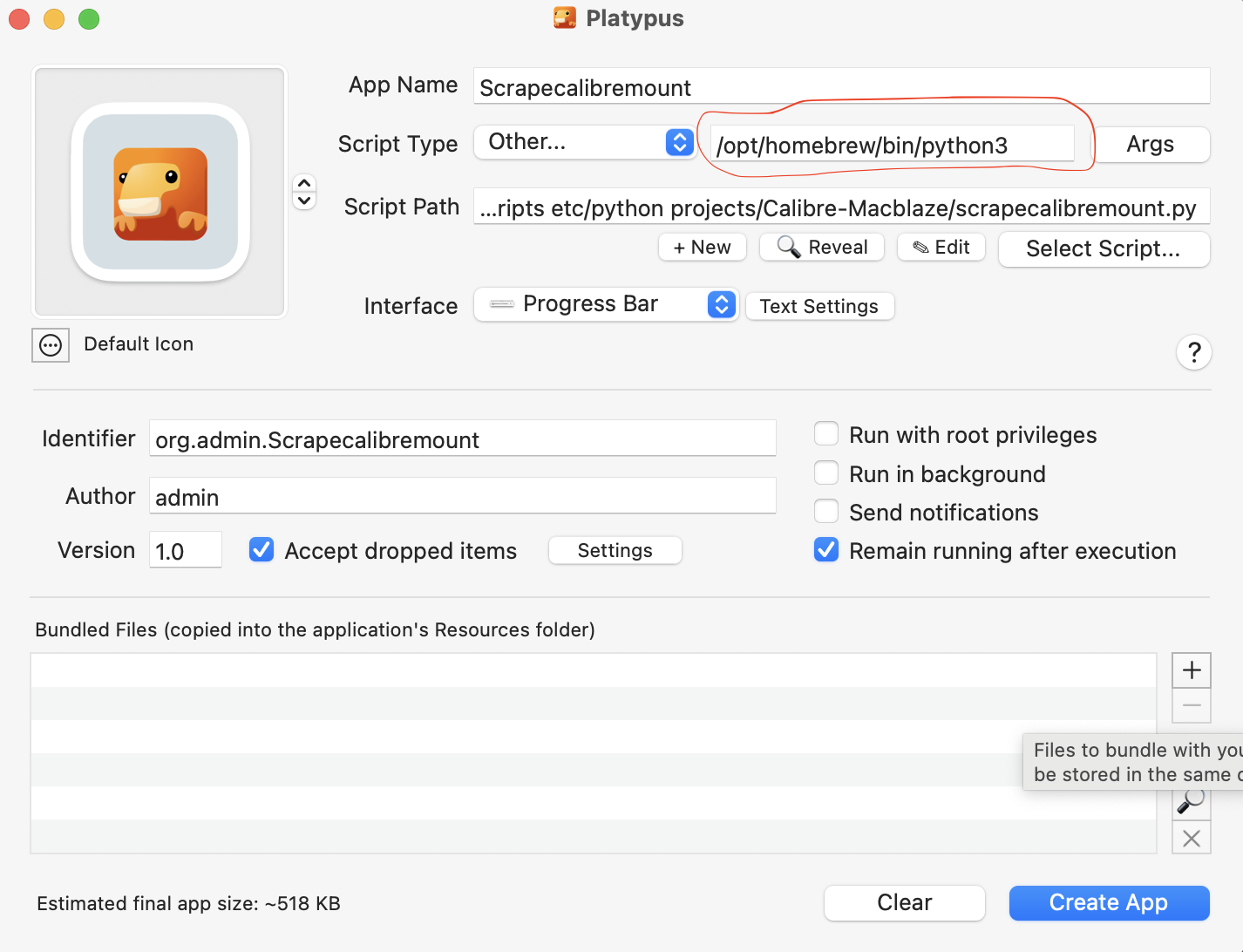
Calibre Web Scraping Update
Stupid security
One of the recent updates to Calibre Web (I am on v0.6.14 now) introduced some security to the login in the form of a csfr token. I had no idea why my script wouldn’t work anymore until I started taking it all apart.
What I ended up having to do was use Beautiful Soup to load the html content of the login page, find the csfr_token and then add it to the login data. I also added in the cookies, although frankly by that time I wasn’t sure if it was necessary or not. But it works so I left it.
Just a note, if any of you have found this page wanting to scrape Calibre-Web, if you search the site for the tag calibre you find the whole journey
The current python script
#! /usr/local/bin/python3
# coding: utf-8
# python script to import shelfs of books from Calibre-Web
# and save them as a markdown file
# import various libraries
import requests
from bs4 import BeautifulSoup
import re
import os
# enable sys.exit()
import sys
# set header to avoid being labeled a bot
headers = {
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
# set base url
urlpath = 'https://MY_CALIBREWEB_URL'
# calibre-web login data
login_data = {
'next': '/',
'username': 'MY_USERNAME',
'password': 'MY_PASSWORD',
'remember_me': 'on',
}
# login as a session
with requests.Session() as sess:
res = sess.get(urlpath + '/login', headers=headers)
login = BeautifulSoup(res._content, 'html.parser')
# find security token and extract value
csrf_token = login.find('input', {'name': 'csrf_token'})
csrf_token = (csrf_token.attrs['value'])
# print(csrf_token)
# append securtiy token to login dictionary
login_data['csrf_token'] = csrf_token
# login with token
res = sess.post(urlpath + '/login', data=login_data, cookies=res.cookies)
# print(res.text)
# set path to export as markdown file
path_folder = "FOLDER_PATH_MOUNTED_BY_SHELL_SCRIPT"
# check ifserver is already mounted and change path if so
if os.path.isdir(path_folder):
print('valid drive')
elif os.path.isdir("/Volumes/www/home/books/"):
path_folder = "/Volumes/www/home/books/"
else:
path_folder = "/Volumes/www-1/home/books/"
# open the file
file = open(path_folder+"bookfile.md", "w")
# Set Title
file.write("# Books Read since 2012\n")
# print("# Books Read\n")
# Set intro blurb
file.write("This is an automatically generated list of books scraped from my Calibre ebook library ( Making A “Books Read” Page ). As a result it does not include any paper books I may have read as they do not exist in that library.\n\nI update it regularly and finally went back and added all the previous years. Links to previous years’ book count posts: \n- 2012 (85)\n- 2013 (95)\n- 2014 (106)\n- 2015 (92)\n- 2016 (101)\n- 2017 (120)\n- 2018 (142)\n- 2019 (123)\n- 2020 (112)\n")
# find list of shelves
shelfhtml = sess.get(urlpath)
soup = BeautifulSoup(shelfhtml.text, "html.parser")
shelflist = soup.find_all('a', href=re.compile('/shelf/[1-9]'))
print(shelflist)
# reverse order of urllist
dateshelflist = (shelflist)
dateshelflist.reverse()
print(dateshelflist)
# loop through sorted shelves
for shelf in dateshelflist:
# set shelf page url
res = sess.get(urlpath+shelf.get('href'))
soup = BeautifulSoup(res.text, "html.parser")
# find year from shelflist and format
shelfyear = soup.find('h2')
year = re.search("([0-9]{4})", shelfyear.text)
year.group()
file.write("\n### {}\n".format(year.group()))
# print("### {}\n".format(year.group()))
# find all books
books = soup.find_all('div', class_='col-sm-3 col-lg-2 col-xs-6 book')
# loop though books. Each book is a new BeautifulSoup object.
for book in books:
title = book.find('p', class_='title')
# print(title)
author = book.find('a', class_='author-name')
#print (author)
seriesnamea = book.find('p', id='series') # I have to manually add this id to the shelf.html template
seriesname = (seriesnamea.text if seriesnamea else "").replace(
" ", "").replace("(", " Book ").replace(")", "").replace("\n", "")
if (seriesname != ""):
seriesname = "*" + seriesname + "*"
#print (seriesname)
# NOTE: pubdate is custom added by me to /templates/shelf and won't work in a standard install
pubdate = book.find('p', class_='series', id='pubdate')
if pubdate:
#print (pubdate)
# extract year from pubdate
pubyear = re.search("([0-9]{4})", pubdate.text)
pubyear.group()
pubyear = pubyear.group()
else:
pubyear = "n/a"
# construct line using markdown
newstring = "* ***{}*** — {} ({})\n{} – ebook\n".format(
title.text, author.text, pubyear.group(), seriesname)
#print (newstring)
file.write(newstring)
file.close()
NOTE—July 18, 2023 Added some new code from various updates (see calibre updates)
Calibre: Lost and Found
After the most recent update to Calibre Web I had an issue logging in. In true me-fashion I screwed around for a bit and then tried reinstalling. It worked. However that overwrote the database that held all my settings and poof! — all my shelves were gone. That was a listing of all my books read from 2015 to now. Grrr.
(As a side note, just as I was mildly panicking about this, L plaintively called my name and informed me she had lost her much beloved sapphire in the garden bed. So off I went to hack and slash the flowerbed to look for it. Luckily a) it’s fall and it needed hacking and slashing and b) it only took about 15 minutes to find it. So all’s well on that score.)
Anyway back at my desk, I was a bit annoyed and went digging around in the file repo (always doing things the hard way…) to try and find where the shelves and their contents might be stored and if they were recoverable. Eventually I realized two small, but significant facts: 1) I had for some odd reason copied the calibre-web folder before reinstalling—I almost never make backups… I must be learning finally! and 2) there is a handy FAQ… duh.
https://github.com/janeczku/calibre-web/wiki/FAQ
What do I do if I lose my “Admin” password?
If there are more than on admin on your instance any other admin can generate a new password for your account. If the only admin forgot his password: You are in trouble. Currently no password reset function is implemented. The only option would be editing the password in the app.db with a sqlite Database editor, or starting from the beginning.How to Backup Calibre-Web Settings?
All settings of Calibre-Web are stored in the app.db in the root folder of the project.If you are using Google Drive as ebook storage than you also need to backup the gdrive.db, settings.yaml and gdrive_credentials files.
So obviously the info was in the app.db file! I then spent about 15 minutes trying to download a SQLite editor (DB Browser for SQLite https://sqlitebrowser.org/dl/) via brew (brew install --cask db-browser-for-sqlite) which helpfully installed an app in the Applications folder. Then I dug around for another 5 minutes trying to figure out the SQL statement to import the data from the backup database into the active database until the lightbulb went off (of the low wattage LED variety if that matters) it occurred to me that was completely unnecessary.
Just copy the backup app.db over the current app.db you idiot…but make a backup first!
So I did.
And it worked.
All’s well that ends well.

Launch CalibreWeb automatically on boot
In an ongoing attempt to make some of my systems automatic and bullet-proof I decided to try and get my CalibreWeb server to boot at startup. This, in conjunction with my autofs setup should have made my CalibreWeb site able to withstand a reboot of either the CalibreWeb host or the computer hosting the database (see below for more on this).
Normally on a Mac (and this is hosted on my old Mac mini which serves as our media server) you just add the program to Login Items in the User control panel and voila.
But since CalibreWeb is a python program and needs to be executed via command line this is a bit tougher. A bit of googling and this is the solution I came up with…
Make a plist
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>Label</key>
<string>calibre.launcher</string>
<key>ProgramArguments</key>
<array>
<string>/usr/local/bin/python3</string>
<string>pythonweb/calibre-web-master/cps.py</string>
</array>
<key>StandardErrorPath</key>
<string>/var/log/python_script.error</string>
<key>KeepAlive</key>
<true></true>
</dict>
</plist>
The first array string is where your python executable resides — in my case python3; the second array string is where your calibre-web executable is. I am not sure but I think that the Label string needs to match the file name — at least that seems to be the standard.
And Then
Save it as something like calibre_launcher.plist
Then you need to copy it to: ~/Library/LaunchAgents/ Apparently you can do it also to /Library/LaunchAgents/ but I couldn’t seem to get the permissions correct to be able to do that. And since the computer always boots into a specific user it was ok in the user library folder.
I also had to fix permissions: chmod +x ~/Library/LaunchAgents/calibre_launcher.plist to make it executable and run: launchctl load ~/Library/LaunchAgents/calibre_launcher.plist to activate it. (You can also run: launchctl unload ~/Library/LaunchAgents/calibre_launcher.plist to remove the script from the launch queue.)
Now it should run whenever you boot up.
CalibreWeb Update
It all works. But… it seems if I break the connection between the CalibreWeb python script and the database it won’t recover even when the database becomes available again. So ultimately if I reboot my main computer I still have to restart the CalibreWeb python script.
I currently do this with a bash script (actually I think its now a zsh script…lol). It ssh’s into the media server, kills the python script and then restarts it. Note: I have ssh set up with key pairs so I don’t need to have my password in the script.
#!/bin/zsh echo "pkill -f /pythonweb/calibre-web-master/cps.py" | ssh '<USER>@mini-media-server.local' /bin/zsh echo "Killed Calibre Web..." echo "/usr/local/bin/python3 /pythonweb/calibre-web-master/cps.py &>/dev/null & " | ssh '<USER>@mini-media-server.local' /bin/zsh echo "Restarted Calibre Web..."
Save the above as a text file called something like restartcalibreweb.sh and then chmod +x restartcalibreweb.sh to make it executable. Then you can just double click on it whenever you need to restart the remote CalibreWeb python script. The next idea is to make this script run at bootup as well, but I am as yet unsure if the autofs solution will reload the share before this script runs. If it doesn’t then the CalibreWeb will restart but give me the “locate database” screen because it can’t find the share and I will still have to vnc in to the media server and reconnect.
Note from future self: I never did get this to work properly. Sigh
Auto mount network shares: autofs
Edited to make it work correctly
- It wasn’t surviving reboots
- I had given my mac a permanent IP for another reason so I decided to use that
- I renamed the Calibre Library share to Calibre-Library in order to get rid of the pesky space/em>
- I was also attempting to get Calibre-Web to run from a LaunchDaemon
Apparently there is a BSD utility called autofs that mounts network drives on demand. And with OS X’s unix underpinnings this means it works on your Mac.
This is revolutionary. If you’ve worked in a server environment or tried to store your iTunes or iPhoto library on an external drive you will know, things like network outages, reboots or even taking your laptop offsite will mean you have to reconnect, which while not arduous, is a bit annoying and often hard to explain to users.
In my case I run Calibre-Web on my mac-mini server but house the calibre db on my personal machine. Which means I resorted to writing a script to reconnect every time I rebooted something…which seemed to be be pretty often.
The code
Disclaimer: this is the code for my old mac mini which is stuck on High Sierra 10.13.6. I have read (see links below) that it works slightly differently for newer versions of OS X.
First off edit the auto_master file to insert the auto_smb line and comment out the /net line:
sudo nano /etc/auto_master
#
# Automounter master map
#
/mount auto_smb
+auto_master # Use directory service
#/net -hosts -nobrowse,hidefromfinder,nosuid
/home auto_home -nobrowse,hidefromfinder
/Network/Servers -fstab
/- -static
Then you will create the config file you specified above (auto_smb):
sudo nano /etc/auto_smb
The first bit is the location of the share. In this case I called it calibre and wanted it to mount in the volumes folder with all the the rest of the regular mounts.
Then you need to add the login information including your name and password and the network location. An IP will work just as well if you are using a static one.
Calibre-Library -fstype=smbfs,rw ://username:password@192.168.1.20/Calibre-Library
Other Uses
At some point I am going to move L’s ever-growing music library to something like a NAS (network attached storage) and this will be a godsend if it works the way it has so far. Fingers crossed.
Sources
https://useyourloaf.com/blog/using-the-mac-os-x-automounter/
Afterword
After all that, it doesn’t solve the problem I thought it would. When my mac hosting the calibre library goes down it send the python code in Calibre-Web into an unrecoverable tailspin. So even though the share comes back up it still needs a restart to make it happy again. So I am only halfway there.
900: My Library in 2021
I own 863 books. Well I might own a few more here and there (books that I have worked on but not necessarily “read” etc.) but my main library — of mostly SF/Fantasy — consists of 863 titles. It took me almost 40 years to accumulate those.


Yes, I have a spreadsheet. I also haven’t bought a new book in 10 years…for certain definitions of “book.”
Ebooks
On the other hand, today I bought my 900th ebook.
For Xmas in December 2009, L bought me my first ereader—a Sony Reader PRS-600 (read about it here). I was suspicious but willing to give it a chance. On January 1, 2010 I bought my first ebook: March to the Stars by David Weber and John Ringo from Baen for $5 usd (the same book is now $6.99). I chose a Baen book (and generally still do) because of their non-drm policy.
So, since 2010, I have accumulated more ebooks in ~10 years than I did in the preceding 45. That says something about me, but I am not sure exactly what 🙂
Number 900?
I decided on Steven Brust’s The Baron of Magister Valley —a very under-marketed book published last year that I didn’t realize even existed until very recently. I have been trying very, very hard not to acquire any new books in order to get my To-Read pile down. I can happily announce that, other than a pile of “backup book” (classics and freebies that I have in case of emergency but don’t really intend to read unless I have to), I was down to 3. Woohoo!
So I went on a buying spree: A Desolation Called Peace by Arkady Martine, Martha Wells’ Fugitive Telemetry —number 6 of awesome The Murderbot Diaries and The Assassins of Thasalon (Penric & Desdemona) from Lois McMaster Bujold. Which brought my ebook count to 899.

Well, what’s a fella to do? Buy another book of course. Despite it costing $14.99. Seriously? Fifteen bucks?
Whatever.

But it’s done. And now happy reading!
Calibre Web 2021
A recent update to Calibre Web version .6 added the series info, so there is no longer a need to add that to the templates. And they did make a few changes to the code for the publishing date.
Reminder You can edit the script through View Package Contents
Now to add the pub date so my python web scraping program can access it:
After ~line 71 on /cps/templates/shelf.html
{% if (entry.Books.pubdate|string)[:10] != '0101-01-01' %}
<p class="series" id="pubdate">{{entry.Books.pubdate|formatdate}} </p>
{% endif %}
—just after the {% endif %} for the series section.
Remember to go to Admin and restart Calibre before exporting.
Note: updated March 2022
– to change the class to “series” to match the previous lines and add an id of “pubdate” for the script to search for.
Note: updated July 2022
– changing the class to “series” caused “pubdate”to show up if there was no series. So I added id=”series” to the preceding {if} as well (see below) — around line 64 — and then searched for id rather than class in the python script.
{% if entry.Books.series.__len__() > 0 %}
<p id="series" class="series"p>
Note: updated Oct 2022
The source code was changed from entry.pubdate to entry.Books.pubdate (and all other calls — see series above)
Note: Update April 2024
Edited opds.py to enable Homepage widget: https://github.com/janeczku/calibre-web/commit/0499e578cdd45db656da34cd2d7152c8d88ceb23#diff-4ec64b67724eadd1f9c30601b50791079ee157b6bf63c411ce68d637c9793f1dR416-R425
Books Read & Calibre Web Update
Previously (Making A “Books Read” Page) I had posted how I added info to the default Calibre Web templates to add the Series and Pub date information so I could scrape it. Well, it’s gotten a bit more complex since then. Someone added a similar mod to the Github repository which has not yet been incorporated. They didn’t add the pub dates, but did add the series to a few more pages so I thought I would restate my changes here for future reference.
/templates/shelf.html
Add both series info and pub date for the python web scraping program to access:
{% if entry.series|length > 0 %}
<p class="series">
{{_('Book')}} {{entry.series_index}} {{_('of')}} <a href="{{url_for('web.books_list', data='series',sort='abc', book_id=entry.series[0].id)}}">{{entry.series[0].name}}</a>
</p>
{% endif %}
{% if entry.pubdate[:10] != '0101-01-01' %}
<p class="publishing-date">{{entry.pubdate|formatdate}} </p>
{% endif %}Added around line 45 (just after the {% endif %} for the author section).
/templates/index.html
Add only series info just for aesthetics (note the code is from the proposed mod and is slightly different):
{% if entry.series.__len__() > 0 %}
<p class="series">
<a href="{{url_for('web.books_list', data='series', sort='new', book_id=entry.series[0].id )}}">
{{entry.series[0].name}}
</a>
({{entry.series_index}})
</p>
{% endif %}
Added around line 193 111 (just after the {% endif %} for the author section). (This might be 36… there seems to have been a change…)
/templates/discover.html
{% if entry.series.__len__() > 0 %}
<p class="series">
<a href="{{url_for('web.books_list', data='series', sort='new', book_id=entry.series[0].id )}}">
{{entry.series[0].name}}
</a>
({{entry.series_index}})
</p>
{% endif %}
Added around line 36 (just after the {% endif %} for the author section).
I am trying to figure out a way to automate the mods if the main repository doesn’t decide to incorporate the changes but so far an elegant solution eludes me.
Making a “Books Read” page
So recently I came across a web page called How I manage my ebooks by a fellow named Aleksandar Todorovi. He is a developer who wanted to track his reading on his webpage. He introduced me to a Calibre project called Calibre-Web which is basically a web interface for Calibre with a few extra bells and whistles. Reading through his explanation it seemed pretty simple to implement except for this statement:
As a final step in the chain, I have created a script that allow me to publish the list of books I’ve read on my website. Since Calibre-Web doesn’t have an API, I ended up scraping my own server using Python Requests and BeautifulSoup . After about one hundred lines of spaghetti code gets executed, I end up with two files:
books-read.md, which goes straight to my CMS, allowing me to publicly share the list of books I have read, sorted by the year in which I’ve finished reading them.…
The Process
So I set about to try and implement my own version of Aleksandar’s project. In my typical trial and error fashion it took a couple of days of steady work and I learned a ton along the way.
Calibre-Web
I went ahead and downloaded Calibre-Web and wrestled getting it running on my test server (my old mac-mini). It is a python script, which I still a bit fuzzy about the proper way to actually implement. I ended up writing a shell script to run the command "nohup python /Applications/calibre-web-master/cps.py" and them made it executable from my desktop. I still have some work to do there to finalize that solution.
I have to say I really like the interface of Calibre-Web much more than the desktop Calibre and although there are a few quirks, I will likely be using the web version much more than the desktop from now on.
Then I made a few shelves with the books I had read in 2019 and 2020 and was good to go. Now I just needed to get those Shelves onto my website somehow.
Web Scraping
Now I’ve never heard of the term web scraping, but the concept was familiar and it turns out it is quite the thing.
Web scraping, web harvesting, or web data extraction is data scraping used for extracting data from websites
—Web scraping, Wikipedia
The theory being that since all the info is available accessible in the basic code of the Calibre-Web pages, all I needed to do was extract and format it, then repost it to this site. So I did. Voila: My Books Read page.
I guess I skipped the tough part…
Starting out I understood Python was a programming language, but had no idea what Python Requests or BeautifulSoup were. Turns out that Python Requests was essentially one of many “html to text” interpreters and BeautifulSoup was a program (library?…I am still a bit vague on the terminology) to extract and format long strings of code into useful data.
Start with Google
I started by a quick search and found a few likely examples to follow along with.
https://medium.com/the-andela-way/introduction-to-web-scraping-87edf94ac692
https://medium.com/the-andela-way/learn-how-to-scrape-the-web-2a7cc488e017
https://www.dataquest.io/blog/web-scraping-beautifulsoup/
These were helpful in explaining the structure and giving me some basic coding ideas, but I mostly relied on https://realpython.com/beautiful-soup-web-scraper-python/ to base my own code on.
Step one
I got everything running (this included sorting out the mess that is python on my computer, but that is another story) and tried to get a basic python script to talk to my calibre installation. Turns out that even though my web browser was logged into Calibre-Web, my script wasn’t. Some some more googling found me this video (Website login using request library in Python) and it did the trick to write the login portion of my script.
Step two
Then I wrote a basic script that extracted data (much more on this later) and saved it to a markdown file on the webserver. I figured markdown was easier to implement than html and knew WordPress could handle it.
Or could it? Turns out the Jetpack implementation was choking on my markdown file for some reason. I fought with it for a while and eventually decided to see if I could find a different WordPress plugin to do the job. Turned out I could kill two birds with one stone using Mytory Markdown which would actually load (and reload) a correctly formatted remote .md file to a page every time someone visited.
Step three
After I got a sample page loaded on the website I realized that it was missing pub date and series name which, if you have ever visited one of my annual books read posts (Last Books of the decade: 2019, Books 2018—Is this the last year? etc.) is essential information. So I had to go into the Calibre-Web code and add those particular pieces of info to the shelf page so I would be able to scrape it all at the same time. I ended up adding this:
{% if entry.series|length > 0 %}
<p class="series">
{{_('Book')}} {{entry.series_index}} {{_('of')}} <a href="{{url_for('web.books_list', data='series',sort='abc', book_id=entry.series[0].id)}}">{{entry.series[0].name}}</a>
</p>
{% endif %}
{% if entry.pubdate[:10] != '0101-01-01' %}
<p class="publishing-date">{{entry.pubdate|formatdate}} </p>
{% endif %}…to to shelf.html in /templates folder of the Calibre-Web install. I added it around line 45 (just after the {% endif %} for the author section). It took a bit of fussing to look good but it worked out great.
Step four
Now all I have to do is figure out how to run my scrape.py script. For now I will leave it a manual process and just run it after I update my Calibre-Web shelves, but making that automatic is on the list for “What’s Next…”
Ta-da
So between this post and Aleksandar’s I hope you have a basic idea of what you need to do in order to try and implement this solution. More importantly when future me comes back and tries to figure out what the hell all this gobbledey-gook mess is I can rebuild the system based on these sketchy notes. I will end this here and continue in a new post on the actual python/beautifulsoup code I came up with to get the web scraping done.